| ||||||||||||||||
| ||||||||||||||||
| ||||||||||||||||
|
Секционированные таблицы и индексы SQL Server 2005 Не смотря на то, что секционированные таблицы и индексы всегда были неотъемлемой частью больших баз данных, призванной улучшать их производительность и управляемость, в Microsoft SQL Server 2005 появились новые возможности, упрощающие процесс разработки таких решений. Данный доклад посвящен эволюции секционирования таблиц в SQL Server: от ручного секционирования данных путем предварительного создания таблиц в качестве подготовительного шага (в SQL Server 7.0 и SQL Server 2000) до процедур реального секционирования таблиц. В SQL Server 2005 новые табличные функции секционирования значительно упрощают разработку и администрирование секционированных таблиц, в месте с тем еще более увеличивая их производительность. Основная задача статьи - составить для Вас представление о секционировании в SQL Server 2005, о том зачем, где и как применять его с большей пользой для Ваших сверхбольших баз данных (VLDB - Very Large Database). Но несмотря на то, что секционирование в SQL Server 2005 нацелено прежде всего на работу с VLDB, следует помнить, что не все базы данных большие с самого начала. SQL Server 2005 обеспечивает гибкость и производительность, значительно упрощая создание и обслуживание секционированных таблиц. Прочтите эту статью, чтобы получить подробную информацию о том, почему Вам стоит знать о секционированных таблицах, что они могут Вам предложить, и, наконец, как разрабатывать, реализовывать и обслуживать секционированные таблицы. СОДЕРЖАНИЕ
Для чего нужно секционирование? Прежде, чем говорить о том, как осуществлять
секционирование и использовать его возможности, сначала нужно
понять, насколько оно необходимо, что такое секционирование и
кому стоит его использовать? Когда Вы создаете таблицы, Вы
проектируете их таким образом, чтобы хранить информацию о
сущностях, например, о покупателях или продажах. Каждая
таблица должна иметь атрибуты, которые описывают только эту
сущность, и, например, для всех покупателей и продаж
исторически сложилось так, что все Ваши покупатели и все Ваши
продажи создаются в соответствующих таблицах. Концепция секционирования для SQL Server не нова. По сути, секционирование в разных формах присутствовало в каждом релизе. Однако, без функций, помогающих в создании и поддержке вашей схемы секционирования, секционирование было неудобным. А, как правило, если инструмент неудобен в работе, то и преимущества от технологии уменьшаются. Тем не менее, из-за существенного выигрыша в производительности, присущего секционированию, с SQL Server 7.0 началось его усовершенствование, от секционированных представлений, поддерживавших некоторые формы секционирования, до наиболее усовершенствованных секционированных таблиц в SQL Server 2005. Ручное секционирование Объектов в версиях, предшествовавших SQL Server 7.0 В SQL Server 6.5 и более ранних версиях, секционирование должно было быть частью вашего проекта, а заодно и встраивалось во все ваши инструкции доступа к данным и запросы. Путем создания нескольких таблиц, и затем управления доступом к необходимым таблицам через хранимые процедуры, представления или клиентские приложения, вы могли часто улучшить производительность некоторых операций, но за счет сложности разработки. Каждый пользователь и разработчик должны были знать и должным образом ссылаться на соответствующие таблицы. Каждая секция создавалась и управлялась отдельно, а представления использовались, для упрощения доступа; тем не менее, это решение давало некоторые преимущества. Когда для упрощения пользовательского и программного доступа применялось объединенное представление (использующее инструкцию UNION), процессор запросов должен был получить доступ к каждой базовой таблице, чтобы определить, находись ли в ней данные, необходимые для результирующей выборки. Если для выполнения запроса была необходима только часть тех базовых таблиц, то каждый пользователь или разработчик должны были разбираться в модели данных, чтобы ссылаться только на необходимые таблицы. Секционированные Представления в SQL Server 7.0 Основные претензии, которые предъявлялись к ручному
созданию секций в версиях, предшествовавших SQL Server 7.0,
касались в первую очередь производительности. В то время как
представления упростили разработку приложений,
пользовательский доступ и написание запросов не упростились. С
выпуском SQL Server 7.0, представления были объединены с
ограничениями целостности, что позволило оптимизатору запросов
удалять лишние таблицы из плана исполнения запроса (т.е.
исключать секции) и значительно уменьшать стоимость плана
исполнения, когда объединенное (UNIONed) представление
обращалось к нескольким таблицам. 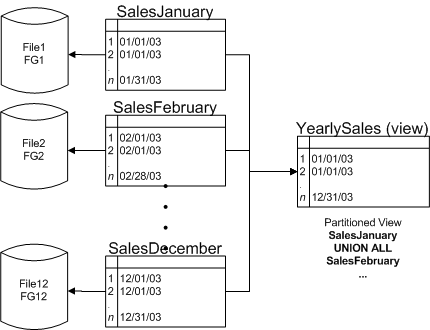 Рисунок 1: Секционированные представления в SQL Server 7.0/2000 Пользователи, которые будут обращаться к представлению YearlySales со следующим ниже запросом, будут адресоваться ТОЛЬКО к таблице SalesJanuary2003.
Пока ограничения целостности являются "доверительными" ("trusted"), и запросы к представлениям используют инструкцию WHERE для ограничения результатов выборок, основываясь на ключе секционирования (столбце, по которому определено ограничение целостности), до тех пор SQL Server будет обращаться только к необходимым базовым таблицам. "Доверительное" ограничение целостности - это ограничение целостности, для которого SQL Server в состоянии гарантировать, что все его данные придерживаются свойств, заданных ограничением целостности. По умолчанию, ограничение целостности создается с опцией WITH CHECK. Этот параметр вызывает блокировку схемы таблицы для того, чтобы данные могли быть сверены с ограничением целостности. Ограничение целостности будет добавлено, как только верификация проверит достоверность существующих данных; но если вдруг блокировка схемы будет удалена, последующие операторы INSERT, UPDATE и DELETE должны будут самостоятельно соблюдать ограничения целостности. Благодаря "доверительным" ограничениям целостности, разработчики могут значительно упростить создание представлений, поскольку им уже не нужно напрямую обращаться к интересующим их таблицам. Благодаря "доверительным" ограничениями целостности SQL Server улучшает производительность запросов, исключая ненужные таблицы из плана исполнения. Примечание: ограничение целостности может стать "не доверяемым" ("untrusted") по нескольким причинам; например, если при выполнении оператора bulk-insert не задан аргумент CHECK_CONSTRAINTS. Как только ограничение целостности станет "не доверяемым", процессор запросов вернется к сканированию всех базовых таблиц, поскольку нет никакого способа подтвердить, что запрашиваемые данные действительно расположены в искомой таблице. Секционированные Представления в SQL Server 2000 Не смотря на то, что SQL Server 7.0 значительно упростил разработку и улучшил производительность операторов SELECT, операторы модификации данных не претерпели никаких изменений; операторы INSERT, UPDATE и DELETE поддерживались только для базовых таблиц, и не поддерживались для представлений, объединявших наборы данных (с помощью оператора UNION). SQL Server 2000 позволил операторам модификации данных также извлекать выгоду из возможностей секционированных представлений, разрешая через представления модифицировать соответствующие базовые таблицы. И хотя существуют дополнительные ограничения на создание ключа секционирования, тем не менее, основной принцип заключается в том, что не только операторы SELECT, но и операторы модификации данных будут направляться непосредственно соответствующим базовым таблицам. За более полной информацией об ограничениях, настройке, конфигурации и некоторых приемах секционирования в SQL Server 2000 вы можете обратиться к статье: екционированные Таблицы в SQL Server 2005 В то время как усовершенствования SQL Server 7.0 и SQL
Server 2000 значительно улучшили производительность
секционированных представлений, они не упрощали их
администрирования, разработки или развертывания. Все таблицы,
на основе которых строилось секционированное представление,
создавались и управлялись по отдельности. Разработка
приложений становилась проще за счет того, что разработчику
уже не приходилось обращаться непосредственно к базовым
таблицам, однако администрирование было затруднено, поскольку
приходилось управлять каждой отдельной таблицей, входящей в
состав секционированного представления, и его ограничениями
целостности. Из-за сложностей управления, разделение таблиц
зачастую использовалось только тогда, когда данные нужно было
"заархивировать" или загрузить. Операции добавления/удаления
из доступной только на чтение таблицы (read-only) были слишком
дорогостоящими - они занимали время, место в журнале
транзакций, и часто создавали блокировки. Еще лучше обстоят дела в случае, если данные необходимо
удалить. Если база данных нуждается только в "sliding window"
("скользящее окно") наборе данных, то, когда новые данные
будут готовы к переселению (например, в текущий месяц), тогда
самые старые данные (например, данные того же месяца за
предыдущий год) смогут быть удалены. В этом случае, Вы,
вероятно, добьетесь улучшения производительности от
использования секционирования на несколько порядков. Поскольку
это может показаться неправдоподобным, давайте рассмотрим
имеющиеся тут отличия. А кроме того, знаете ли Вы, что использование файловых групп (filegroups) совместно с секциями является идеальным механизмом секционирования? Файловые группы позволяют Вам размещать отдельные таблицы на различных физических дисках. Если отдельная таблица располагается в нескольких файлах, благодаря использованию filegroups, то тогда фактическое расположение данных предсказать невозможно. В системах, которые не допускают параллельной обработки данных, SQL Server, благодаря применению файловых групп, улучшает производительность за счет использования всех дисков более равномерно и поэтому конкретное размещение данных в них не является столь принципиальным. На Рисунке 2 представлена файловая группа, состоящая из трех файлов. В ней располагаются две таблицы: Orders и OrderDetails. Когда данные таблиц размещаются в файловой группе, SQL Server пропорционально заполняет файлы файловой группы, захватывая в них необходимое дисковое пространство для своих объектов экстентами (кусками по 64 Kb, что равно 8 страницам данных по 8 Kb). В момент создания таблиц Orders и OrderDetails файловая группа будет пуста. Когда приходит новый заказ, в таблице Orders создается соответствующая запись, и по одной записи в таблице OrderDetails для каждого заказанного товара. SQL Server выделяет один экстент для таблицы Orders в File1, и затем еще один экстент для таблицы OrderDetails в File2. По всей вероятности, таблица OrderDetails будет расти быстрее, чем таблица Orders, и поэтому следующие несколько экстентов будут выделены для нее: следующий экстент для таблицы OrderDetails будет располагаться в файле File3. На приведенном ниже рисунке продемонстрировано размещение экстентов данных таблиц Orders и OrderDetails в файловой группе. 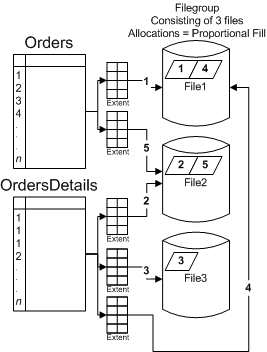 Рисунок 2. Пропорциональное заполнение файлов SQL Server и дальше продолжит балансировать (уравновешивать) размещение всех объектов в пределах этой файловой группы. Наряду с тем, что SQL Server получает выгоду от использования большего количества дисков для данной операции, это не так оптимально с точки зрения управления или перспективы обслуживания (лишние неудобства), или для ситуации, когда модели использования достаточно предсказуемы (и обособлены). В SQL Server 2005 секционированная таблица может быть спроектирована (используя "функции" и "схемы") таким образом, чтобы строки, имеющие одинаковый ключ секционирования, размещались бы в строго указанном месте. Функция секционирования определяет границы секций и то, в какую секцию должно быть занесено первое значение. В случае LEFT-функции, первое значение будет являться верхней границей в первой секции. В случае RIGHT-функции, первое значение будет являться нижней границей во второй секции. Мы еще рассмотрим подробно особенности функций секционирования дальше в этой статье. Как только функция определена, может быть создана схема секционирования для того, чтобы определить физическое расположение секций в базе данных. Если несколько таблиц используют одну и ту же функцию (но не обязательно одну и ту же схему), строки, имеющие один и тот же ключ секционирования, будут располагаться на диске вместе. Этот принцип называется выравниванием. Выравнивая строки нескольких таблиц по ключу секционирования, SQL Server может (если оптимизатор запросов предпочтет) работать только с необходимыми группами данных (в каждой из таблиц). Для того чтобы выровняться, две секционированные таблицы или два индекса должны иметь некоторое соответствие между их соответствующими секциями. Они должны использовать "эквивалентные" функции секционирования и быть связаны по столбцам секционирования. Две функции секционирования могут использоваться для выравнивания данных, если:
Внимание! Даже если две функции секционирования рассчитаны на выравнивание данных, ваши таблицы могут остаться не выровненными из-за не выровненных индексов, если они не секционированы по тем же столбцам, что и таблицы. Локализация (Collocation) - более строгая форма выравнивания, когда два выровненных объекта объединены с предикатом equi-объединения (inner), где equi-объединение производится по столбцу секционирования. Это становится важным в контексте запроса, подзапроса или другой подобной конструкции, где могут встретиться предикаты equi-объединения. Локализация эффективна, поскольку запросы, объединяющие таблицы по столбцам секционирования, выполняются тогда значительно быстрее. Возьмем, например, таблицы Orders и OrderDetails, описанные выше. Вместо того чтобы заполнять файлы пропорционально, Вы можете создать схему секционирования, которая разнесет БД по трем файловым группам. Вы определяете таблицы Orders и OrderDetails таким образом, чтобы они использовали одну и ту же схему. Связанные данные (по ключу секционирования) будут помещены в один и тот же файла, таким образом, изолируя необходимые для объединения данные. Когда связанные строки из нескольких таблиц секционированы по одному и тому же принципу, SQL Server может объединять секции, не имея необходимости рыться во всей таблице или нескольких секциях (если к таблицам применялись разных функций секционирования) для сопоставления строк. В этом случае, объекты не просто выровнены, они, как говорится, являются выровненным хранилищем, поскольку связанные данные располагаются в одних и тех же файлах. Следующий рисунок демонстрирует, как два объекта могут использовать одну и ту же схему секционирования, когда все строки данных с одинаковым ключом секционирования окажутся в одной и той же файловой группе. Когда связанные данные выровнены, SQL Server 2005 может эффективно работать с большими наборами данных параллельно. Все данные о продажах за январь (как для Orders, так и для OrderDetails) будут располагаться в первой файловой группе, данные за февраль - во второй файловой группе и т.д. 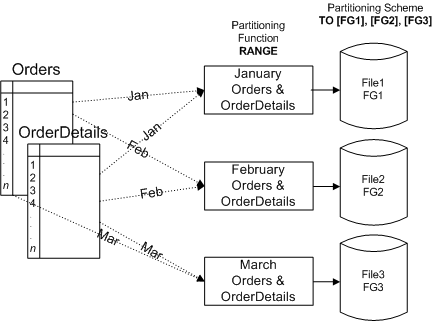 Рисунок 3. Таблицы выровненных хранилищ SQL Server поддерживает секционирование, основанное на
диапазонах. Таблицы, так же как и индексы могут использовать
одну и ту же схему для лучшего выравнивания. Хорошее
проектирование способно значительно улучшить
производительность системы, но что, если использование данных
все время меняется? Что, если потребуется дополнительная
секция? Простота администрирования при добавлении и удалении
секций, а также управления секциями извне секционированной
таблицы была главной целью при разработке SQL Server
2005.
Чтобы создавать секции в SQL Server 2005, Вам необходимо познакомиться с несколькими новыми понятиями, терминами и синтаксисом. В предыдущих выпусках SQL Server таблица была всегда физическим и логическим понятием, теперь в SQL Server 2005 для Секционированных Таблиц и Индексов у вас есть на выбор несколько вариантов того, как и где хранить таблицу. В SQL Server 2005, таблицы и индексы могут быть созданы с точно таким же синтаксисом, как и в предыдущих релизах - как простая табличная структура, помещенная в DEFAULT filegroup или определенную пользователем файловую группу (user-defined filegroup). Кроме того, в SQL Server 2005 таблица и индексы также могут быть основаны на схеме секционирования. Схема секционирования отобразит объект на одну или возможно несколько файловых групп. Для определения того, какие данные где размещать, схема секционирования использует функцию секционирования. Функция секционирования определяет алгоритм, используемый для маршрутизации строк, а схема связывает секции с их соответствующим физическим местоположением (т.е. файловой группой). Другими словами, таблица по-прежнему является логическим понятием, но её физическое расположение на диске может радикально отличаться от более ранних выпусков SQL Server; таблица может иметь схему. Диапазонные секции - это табличные секции, описанные определенными и настраиваемыми диапазонами данных. Границы диапазонных секций выбираются разработчиком, и могут быть изменены, если изменится модель использования данных. Как правило, эти диапазоны основываются на дате или на упорядоченных группировках данных. Основное применение диапазонных секций - архивирование
данных, поддержка принятия решений (когда зачастую необходимы
только определенные диапазоны данных, например, только
заданный месяц или квартал), и объединение OLTP и DSS
(Decision Support System - система поддержки принятия
решений), где использование данных меняется в течение всего
жизненного цикла записи базы данных. Самое большое
преимущество новой технологии (особенно для архивирования и
обслуживания) состоит в способности манипулировать крайне
специфичными диапазонами данных. Диапазонные секции архивируют
старые данные и загружают новые чрезвычайно быстро. Секции
диапазона лучше всего подходят для ситуации, когда доступ к
данным осуществляется для поддержки принятия решений и
основывается на больших диапазонах данных. В этом случае Вы
заботитесь о том, где конкретно расположены данные, так чтобы
обращение велось только к подходящим секциям. Когда появляются
новые бизнес - данные, Вы естественно захотите добавлять их -
легко и быстро. 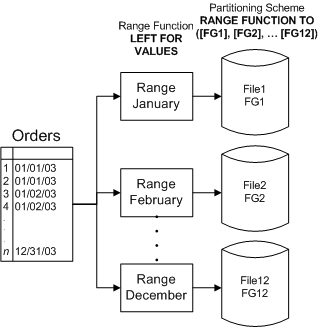 Рисунок 4: Диапазонная секционированная таблица - 12 Секций. Определение ключа секционирования Первый шаг в секционировании таблиц и индексов состоит в определении "ключа". Ключ секционирования - это столбец(ы) таблицы, который удовлетворяет определенным критериям. Функция секционирования определяет тип данных, на котором базируется логическое разделение данных. Физическое размещение данных определено схемой секционирования. Другими словами, схема отображает данные на файловые группы, которые в свою очередь отображают данные на конкретные файлы. Для этого схема всегда использует функцию - если функция определяет пять секции, тогда схема должна использовать пять файловых групп. Однако совсем не обязательно, чтобы все файловые группы были разными; тем не менее, Вы получите больший выигрыш в производительности, если будете использовать систему из нескольких дисков, предпочтительно многопроцессорную. При использовании схемы вы определяете столбец, который будет выступать в качестве аргумента для функции секционирования. Данные в диапазонных секциях разделены логически. Фактически, секции данных в действительности не могут быть сбалансированы вообще. Однако использование данных навязывает диапазонную секцию, поскольку модель использования этой таблицы определяет специальные границы для анализа (иначе называемые "диапазонами"). Ключ секционирования для диапазонной функции может состоять только из одного столбца, и функция секционирования будет включать всю область данных, даже если эти данные недопустимы для таблицы. Другими словами, границы определены для каждой секции, но первая и последняя секции позволят включать бесконечно малые (первая) и бесконечно большие (последняя) значения. Для секций должны быть заданы ограничения целостности CHECK для реализации Ваших бизнес-правил и обеспечения целостности данных (т.е. ограничения области данных конечным, а не бесконечным диапазоном). Диапазонные секции идеальны, когда обслуживание и администрирование требуют архивирования больших диапазонов данных на регулярной основе, и когда запросы обращаются к большим массивам данных - но только в пределах нескольких диапазонов. Секционировать можно не только данные, но и индексы.
Индексы можно секционировать с помощью той же функции, что и
базовую таблицу, либо любой другой. Однако с точки зрения
производительности лучше всего разделять таблицу и ее индексы,
используя одну и ту же функцию. Если таблица и индексы
используют одну и ту же функцию секционирования, и
секционируются по одним и тем же столбцам (в том же порядке),
такая таблица и индексы называются выровненными. Если индекс
создается по уже секционированной таблице, SQL Server
автоматически выровняет новый индекс согласно схеме
секционирования таблицы, если только индекс явно не
секционирован по-другому. Если таблица и ее индексы выровнены,
тогда SQL Server может перемещать секции внутри
секционированных таблиц более эффективно, поскольку все
связанные данные и индексы разделены по одному
алгоритму. Особые режимы секционирования - Split, Merge и Switch В SQL Server 2005 для помощи в управлении секционированными
таблицами введено несколько новых понятий. Поскольку
секционирование применяется к большим таблицам для обеспечения
масштабируемости и поддержания лучшей производительности этих
таблиц, весьма вероятно, что количество секций, выбранное в
момент создания функции секционирования, со временем
изменится. Используя оператор ALTER TABLE с новой опцией
"split" (“расщепление”), Вы можете добавить в таблицу новую
секцию. Когда секция “расщепляется”, часть данных может быть
перенесена в новую секцию, однако это не лучшее решение с
точки зрения производительности. Ниже в этой статье будет
приведен полный сценарий работы режима “split”. 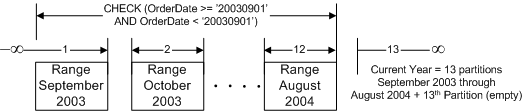 Рисунок 5: Границы диапазонных секций - перед загрузкой данных/архивацией Когда начинается октябрь (в базе данных OLTP), необходимо
переместить данные сентября в секционированную таблицу,
используемую для анализа. Включение/выключение секций в
таблицу - очень быстрый процесс, к тому же, вся
подготовительная работа может быть выполнена из-за пределов
секционированной таблицы. Этот сценарий в подробностях
описывается в учебном примере, который будет рассмотрен чуть
ниже. Его основная идея заключается в использовании “каскадных
таблиц”, которые в конечном счете станут секциями в
секционированной таблице (“включение” таблицы, становящейся
секцией в секционированной таблице) или будут хранить
устаревшие данные таблицы (“выключение” секции, становящейся
автономной таблицей). 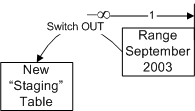 Рисунок 6: Выключение секции Для того чтобы удалить первую (старшую) секцию (сентябрь 2003), необходимо воспользоваться новой опцией “слияния” оператора ALTER TABLE - “merge” (см. Рисунок 7). “Сливая” секции, вы фактически удаляете граничную точку между ними, и, следовательно, устраняете одну из секций (в данном случае сокращая количество секций до 12). Слияние секции будет очень быстрой операцией в том случае, если никакие строки данных не должны быть перемещены; в нашем случае, поскольку первая секция пуста, никакие записи не перемещаются (из первой секции во вторую). Если бы первая секция НЕ была пуста, то при слиянии данные пришлось бы перемещать из первой секции во вторую, и это было бы очень дорогостоящей операцией. Впрочем, в весьма распространенном сценарии “sliding window” (“Скользящее Окно”) это никогда не должно произойти, поскольку Вы всегда будете объединять пустую секцию с активной секцией, и соответственно никакие записи перемещаться не будут. 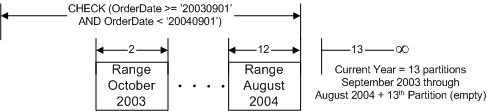 Рисунок 7: Слияние секций И наконец случай, когда новая таблица должна быть включена в секционированную таблицу. Помните, что для того чтобы осуществить включение секции в секционированную таблицу путем простого изменения метаданных, вся работа по загрузке данных и созданию индексов уже должна быть произведена в новой таблице - вне границ секционированной таблицы. Для включения новой секции в таблицу сначала необходимо “расщепить” последний (самый новый, пустой) диапазон на две секции. Кроме того, вам необходимо перестроить ограничение целостности таблицы под требования нового диапазона. Секционированная таблица будет включать 13 секций. Последняя секция в сценарии “Скользящее Окно” с LEFT-функцией секционирования будет всегда оставаться пустой. 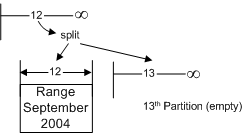 Рисунок 8: Расщепление Секции И наконец, недавно загруженные данные включаются в 12-ую секцию – в качестве данных за сентябрь 2004. 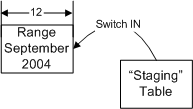 Рисунок 9: Включение Секции В результате мы получаем таблицу такого вида: 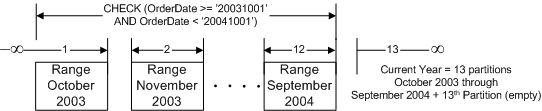 Рисунок 10: Границы диапазонных секций - после загрузки данных/архивации Важно знать, что split и merge – это атрибуты оператора
ALTER PARTITION FUNCTION, а switch – это атрибут оператора
ALTER TABLE. Кроме того, только одна секция может быть
добавлена или удалена единовременно. Если в диапазонную
секционированную таблицу требуется добавить или удалить сразу
несколько секции, то тогда наиболее оптимальным способом
балансировки данных (вместо балансировки целой таблицы для
каждого расщепления) может послужить создание новой
секционированной таблицы – использование новой функции и схемы
секционирования и затем перемещение данных в новую
секционированную таблицу. Для “перемещения” данных сначала
скопируйте их, используя оператор INSERT newtable SELECT …
FROM oldtable, а затем удалите исходные таблицы. Будьте
осторожны, не потеряйте данные, предотвращая пользовательские
(или любые другие) модификации во время этого
процесса. Шаги по созданию секционированных таблиц Теперь, когда у Вас уже сложилось представление о том, для чего создаются и что предлагают секционированные таблицы, неплохо было бы проследить всю логическую цепочку процесса создания секционированной таблицы (см. Рисунок 11). 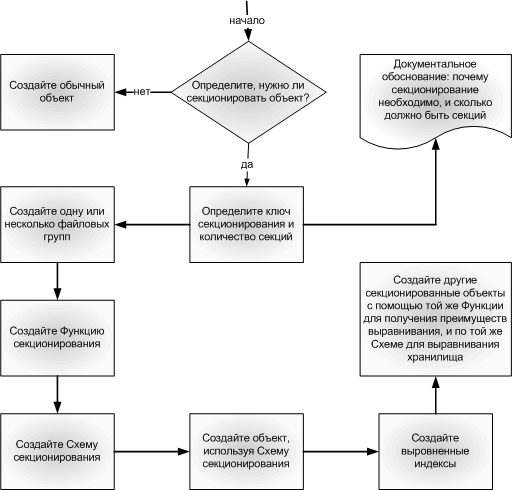 Рисунок 11: Шаги по Созданию Секционированной Таблицы или Индекса Определите, НУЖНО ЛИ секционировать Объект Как уже описано выше - это первый и самый важный шаг. Не
каждая таблица нуждается в секционировании. Не смотря на то,
что секционирование прозрачно с точки зрения приложения, оно
усложняет администрирование и реализацию ваших объектов. В то
время как секционирование может предложить значительные
преимущества, Вы наверняка не станете к нему прибегать для
маленьких таблиц. Так что же считать большим, а что маленьким?
Ваши требования к производительности и обслуживанию, равно как
и текущее состояние этих показателей - вот факторы,
определяющие потребность в секционировании. Определите ключ секционирования и количество секций Если Вы пытаетесь улучшить производительность и управляемость больших подмножеств данных, и существуют определенные модели доступа к ним, используйте механизм диапазонного секционирования. Если ваши данные содержат логические группировки, и Вы часто работаете с только несколькими из этих определенных подмножеств одновременно, тогда определяйте свои диапазоны таким образом, чтобы запросы обращались только к подходящим данным (т.е. секциям). За более подробной информацией вы можете обратиться к разделу BOL: Designing Partitioned Tables and Indexes. Определите, СТОИТ ЛИ использовать несколько файловых групп В целях улучшения производительности и упрощения обслуживания следует использовать файловые группы (filegroups) для разделения данных. Количество файловых групп частично продиктовано аппаратными ресурсами, находящимися в вашем распоряжении; наверняка вам захочется иметь такое же количество файловых групп, что и количество секций, и предпочтительно эти файловые группы будут располагаться на разных дисках. Однако, это в первую очередь относится к системам, где анализ имеет тенденцию быть проводимым по всему набору данных. Если в вашем распоряжении находится мультипроцессорная система, SQL Server может работать с несколькими секциями параллельно и поэтому значительно сокращать общую продолжительность обработки больших и сложных отчетов и аналитических данных. В этом случае, Вы можете получать выигрыш в производительности при параллельной обработке данных, а так же при переключении секций в секционированной таблице. Если Вы хотите разместить секционированную таблицу в нескольких файлах для улучшения сбалансированности подсистемы ввода/вывода, тогда вам следует создать файловую(ые) группу(ы). Файловые группы могут состоять из одного или более файлов, и каждая секция должна отображаться на файловую группу. Одна файловая группа может использоваться несколькими секциями, однако для лучшего управления данными, например, для большей гранулированности резервного копирования, вы должны разрабатывать ваши секционированные таблицы продуманно, так чтобы только связанные или логически сгруппированные данные размещались в одной и той же файловой группе. Используя оператор ALTER DATABASE, Вы добавляете логическое имя файловой группы - той, к которой будут добавлены файлы. Чтобы создать файловую группу с именем "2003Q3" для учебной базы данных AdventureWorks используйте следующий оператор:
После того как вы создадите файловую группу, используйте оператор ALTER DATABASE чтобы добавить файлы в файловую группу.
Таблица создается в файле(ах), определяющем файловую группу; ее местоположение задается в разделе ON оператора CREATE TABLE. Однако без секционирования таблицу нельзя разместить в нескольких файловых группах. Чтобы создать таблицу на основе одной файловой группы, вы используете выражение ON оператора CREATE TABLE. Чтобы создать секционированную таблицу, Вы сначала должны определиться с логикой секционирования. Даже притом, что вы можете определять логические секции для конкретной отдельно взятой таблицы, SQL Server позволяет Вам повторно использовать определение секций и для других объектов. Чтобы отделить понятие "секция" от понятия "таблица" Вы создаете структуру секций посредством функции секционирования. Поэтому первый шаг в секционировании таблицы состоит в создании функции секционирования. CREATE PARTITION FUNCTION для диапазонных секций Диапазонные секции должны быть определены с граничными условиями. Кроме того, все границы должны быть включены; функция диапазонного секционирования должна включать все значения даже притом, что диапазон значений таблицы может быть (и должен быть) более ограниченным (посредством CHECK constraint). Никакие значения (с любого конца диапазона) не должны быть исключены. Кроме того, поскольку данные, вероятно, будут добавляться и удаляться из секции, вам потребуется последняя пустая секция, которую вы сможете постоянно "расщеплять", выделяя тем самым место для новой секции данных. Эта последняя секция будет всегда оставаться пустой, находясь в ожидании новых записей, которые вы будете периодически в нее включать. При диапазонном секционировании вначале определяют
граничные точки. Если Вы определяете пять секции, то
потребуются только четыре граничные точки. Для того чтобы
разделить данные на пять групп, Вы определяете четыре
граничных значения для секций, а затем определяете, какой из
секций будет принадлежать каждое из этих значений: первой
(LEFT) или второй (RIGHT). Для LEFT: Поскольку Ваши диапазонные секции наверняка будут определяться по столбцам с типом данных datetime, то вам следует знать об импликациях (implication - "вовлечение"). Примечание: Импликация (от лат . implico - тесно связываю) - приблизительный логический эквивалент оборота "если..., то..."; операция, формализующая логические свойства этого оборота. Применяя тип данных datetime, Вы всегда используете ОДНОВРЕМЕННО и дату и время. Дата без определенного значения времени подразумевает нулевое время - 12:00am. Если, к примеру, LEFT-функция базируется на этом типе данных, то тогда данные за 1 октября 12:00am попадут в 1-ую секцию, а остальная часть октября - во 2-ую. По логике, лучше всего использовать начальные значения (набора данных второй секции) с RIGHT-функцией и конечные значения (набора данных первой секции) с LEFT-функцией. Три следующих выражения создают логически идентичные структуры секционирования:
Примечание: Использование типа данных datetime добавляет сложности, поскольку Вы должны будете удостовериться в том, что установили правильные граничные значения. В случае с RIGHT-функцией все предельно просто, т.к. время по умолчанию равняется 12:00:00.000am. Для LEFT дополнительная сложность обусловлена точностью типа данных datetime. Причина, по которой вы ДОЛЖНЫ выбирать в качестве граничного значения 23:59:59.997, состоит в том, что тип данных datetime не гарантирует точность в 1 миллисекунду. Вместо этого, datetime-данные абсолютно точны в пределах 3.33 миллисекунд. Значение такта таймера процессора (tick) равное 23:59:59.999 не доступно для SQL Server, вместо этого значение округляется до ближайшего такта, которым является 12:00:00.000am следующего дня. Из-за такого округления границы могут быть неверно определены. Проявляйте осмотрительность при задании значений в миллисекундах для типа данных datetime. Примечание: Функции секционирования также позволяют в качестве определения использовать другие функции. Вы можете использовать функцию DATEADD (ms,-3, '20010101') вместо явного определения '20001231 23:59:59.997'. За дополнительной информацией обратитесь к разделу BOL: "Date and Time" in the Transact-SQL Reference. Для того чтобы хранить по одной четверти данных таблицы Orders в четырех активных секциях (представляющих календарные кварталы) и иметь пятую секцию для последующего использования (в качестве полигона для добавления/исключения данных из секционированной таблицы), используйте такую LEFT-функцию секционирования с четырьмя граничными условиями:
Помните, что четыре граничные точки создают 5 секции - с одной пустой секцией справа, если функция секционирования определена как LEFT, и одной пустой секцией слева, если функция определена как RIGHT. Посмотрите какие наборы данных создаются этой функцией секционирования: Граничная точка '20000930 23:59:59.997' LEFT-ФУНКЦИИ
(задает
модель): Независимо от модели (LEFT или RIGHT), функция диапазонного секционирования должна включать все значения: от бесконечно малого до бесконечно большого. Для функции LEFT последняя граничная точка определит последнее абсолютное значение секций, но поскольку функция должна охватывать всю область данных, то для значений, больших чем значение последней граничной точки, должна существовать заключительная секция. При использовании LEFT-функций всегда будет существовать одна дополнительная секция в конце, и одна дополнительная секция вначале - для RIGHT-функций. Как только Вы создали функцию секционирования, Вы должны связать ее со схемой секционирования, для того чтобы адресовать секции определенным файловым группам. Когда Вы определяете схему секционирования убедитесь, что Вы определили файловые группы для КАЖДОЙ секции, даже если несколько секций будут располагаться в одной и той же файловой группе. Созданная ранее функция OrderDateRangePFN формирует 5 секций, последняя (пустая) будет располагаться в файловой группе PRIMARY. Нет никакой необходимости в особом размещении этой секции, поскольку она никогда не будет содержать данных.
Примечание: Если все секции должны располагаться в одной и той же файловой группе, то в этом случае можно применять упрощенный синтаксис:
Создайте секционированную таблицу Теперь, когда логическая (функция секционирования) и физическая (схема секционирования) структуры определены, таблица может быть секционирована. Таблица определяет, какая "схема" должна использоваться, а схема определяет функцию. Для того чтобы связывать эти три понятия вместе, Вы должны определить столбец(ы) секционирования. Диапазонные секции всегда отображаются исключительно на один столбец таблицы, совместимый с типом данных граничных условий, определенных в функции секционирования. Кроме того, если в таблице необходимо специально ограничивать интервал допустимых значений (а не [- ;+ ]), то следует добавить ограничение целостности (check constraint).
Создайте индексы: секционированные либо обычные По умолчанию индексы, создающиеся в секционированной таблице, будут использовать ту же самую схему секционирования и столбец секционирования, что и таблица. В этом случае индекс будет "выровнен" по отношению к таблице. Выравнивание не является обязательным условием, тем не менее, зачастую желательно, чтобы таблица и индексы были выровнены. Выравнивание таблицы и ее индексов обеспечивает более легкое управление и администрирование, особенно при работе по сценарию "скользящего окна". Не смотря на это, индексы не обязательно должны быть выровнены. Индексы могут быть основаны на других функциях секционирования или не быть секционированы вовсе. Например, в случае, когда создаются уникальные индексы, столбец секционирования должен быть одним из ключевых столбцов; это будет гарантировать то, что для обеспечения уникальности потребуется проверить только подходящую секцию. Поэтому, если Вам необходимо секционировать таблицу по одному столбцу, а создать уникальный индекс по другому столбцу, то тогда они не смогут быть выровнены; индекс может быть либо секционирован по уникальному столбцу (если уникальный ключ основан на нескольких столбцах, то тогда это может быть любой из ключевых столбцов), либо вообще не секционирован. Запомните, что этот индекс должен быть удален и создан заново, если какие-то данные "включаются" или "исключаются" из секционированной таблицы. Примечание: Если Вы планируете загрузить таблицу c существующими данными и затем добавить к ней индексы, то чаще всего наиболее эффективным способом будет загрузка данных в НЕ секционированную, НЕ индексированную таблицу с последующим созданием индексов и секционированием таблицы. Основывая кластерный индекс на схеме секционирования, вы тем самым эффективно секционируете таблицу. Это прекрасный способ секционирования таблиц. Для того чтобы создать таблицу как НЕ секционированную, а кластерный индекс как секционированный кластерный индекс, замените определение ON оператора CREATE TABLE на одну-единственную файловую группу и затем, после того как данные будут загружены, создайте кластерный индекс на основе схемы секционирования. Соберем все воедино: конкретные примеры После знакомства с концепцией, преимуществами и небольшими фрагментами кода, связанного с секционированием, у вас уже наверное сложилось достаточное понимание процесса секционирования. Однако для каждого из шагов доступны специфичные параметры настройки и опции, которые в определенных случаях должны удовлетворять разнообразным критериям. Следующая часть статьи поможет Вам соединить все полученные Вами знания воедино. Секционирование диапазона - сведения о продажах Характер использования сведений о продажах зачастую
изменчив. Как правило, данные текущего месяца - это
оперативные данные; данные предшествующих месяцев - это в
большой степени данные, предназначенные для анализа. Чаще
всего анализ производится ежемесячно, ежеквартально, либо
ежегодно. Поскольку разным аналитикам могут потребоваться
значительные объемы различных аналитических данных
одновременно, то секционирование лучше всего позволит
изолировать их деятельность. В рассматриваемом далее сценарии
данные стекаются из 283 узлов и поставляются в виде двух
файлов стандартного формата ASCII. Все файлы отправляются на
центральный файл-сервер не позднее 3.00 am первого дня каждого
месяца. Размеры файлов колеблются, но в среднем составляют
примерно 86.000 заказов в месяц. Каждый заказ в среднем
составляет 2.63 позиции, поэтому файлы OrderDetails составляют
в среднем по 226180 строк. Каждый месяц добавляется примерно
25 миллионов новых заказов и 64 миллиона строк номенклатуры
заказов. Сервер анализа истории поддерживает данные за 2
последних года. Данные за два года - это чуть меньше 600
миллионов заказов и более 1.5 миллиардов строк в таблице
OrderDetails. Поскольку данные часто анализируются путем
сравнения показателей месяцев одного и того же квартала, либо
одних и тех же месяцев за предыдущие годы, то выбрано
диапазонное секционирование. В качестве размера диапазона
выбран месяц. 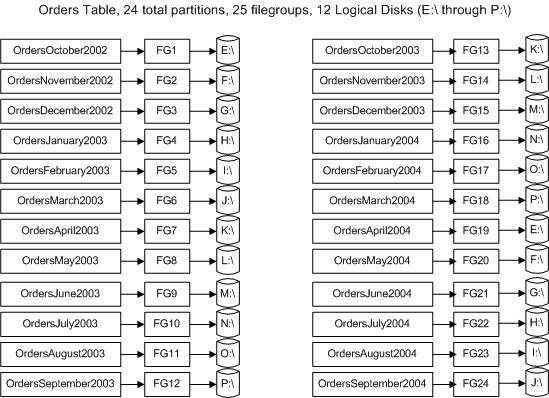 Рисунок 12: Секционированная таблица Orders Каждый из 12 логических дисков использует конфигурацию RAID 1+0, поэтому общее количество дисков, необходимое для таблиц Orders и OrderDetails, равно 48. Не смотря на это, SAN поддерживает до 78 дисков, так что остальные 30 дисков используются для transaction log, TempDB, системных баз данных и прочих небольших таблиц, таких как Customers (9 миллионов записей) и Products (386 750 записей), и т.д. Таблицы Orders и OrderDetails будут использовать одни и те же граничные условия и одно и то же размещение на диске; фактически, они будут использовать одну и ту же схему секционирования. В результате (взгляните на два логических диска E:\ и F:\ на Рисунке 13) данные таблиц Orders и OrderDetails за одни и те же месяцы будут располагаться на одних и тех же дисках: 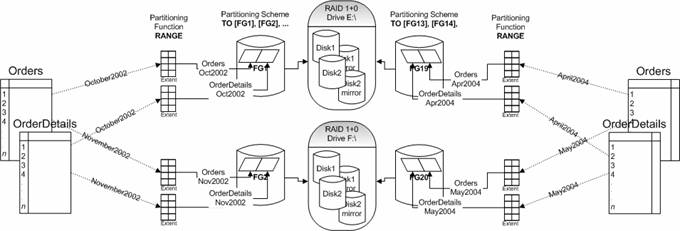 Рисунок 13: Размещение экстентов диапазонных секций на дисковых массивах Хотя это и выглядит запутанным, все это весьма просто реализовать. Самое сложное в создании нашей секционированной таблицы - это доставка данных из большого количества источников - 283 хранилища должны иметь стандартный механизм доставки. Тем не менее, на центральном сервере есть только одна таблица Orders и одна таблица OrderDetails. Чтобы превратить обе таблицы в секционированные, мы должны сначала создать функцию и схему секционирования. Схема секционирования определяет физическое расположение секций на дисках, таким образом, файловые группы также должны существовать. Поскольку для наших таблиц необходимы файловые группы, то следующим шагом является их создание. Синтаксис операторов создания каждой файловой группы идентичен приведенному ниже, тем не менее, данным образом должны быть созданы все двадцать четыре файловые группы.Вы можете поменять названия/расположения дисков на один-единственный диск, для того чтобы протестировать и изучить синтаксис. Убедитесь, что Вы исправили размеры файла на MB вместо GB, и выбрали меньший начальный размер файлов, исходя из доступного вам дискового пространства. Двадцать четыре файла и файловые группы будут созданы в базе данных SalesDB. Все будут иметь схожий синтаксис, за исключением местоположения, имени файла и имени файловой группы:
Как только все двадцать четыре файла и файловые группы
будут созданы, Вы сможете определить функцию и схему
секционирования. Убедиться в том, что ваши файлы и файловые
группы созданы, вы можете при помощи системных хранимых
процедур sp_helpfile и sp_helpfilegroup.
Поскольку и крайне левый, и крайне правый граничные случаи охвачены, эта функция секционирования фактически создает 25 секции. Таблица будет поддерживать 25-ую секцию, которая останется пустой. Для этой пустой секции не требуется никакой специальной файловой группы, поскольку никакие данные не должны когда-либо в нее попасть. Для того чтобы гарантировать, что никакие данные в нее не попадут, constraint ограничит диапазон данных этой таблицы. Для того чтобы направить данные на соответствующие диски используется схема секционирования, отображающая секции на файловые группы. Схема секционирования будет использовать явное определение файловых групп для каждой из 24 файловых групп, содержащих данные, и PRIMARY - для 25-ой пустой секции.
Таблица может быть создана с тем же синтаксисом, который поддерживали предыдущие релизы SQL Server - используя предложенную по умолчанию, либо определенную пользователем файловую группу (для создания НЕ секционированной таблицы) - либо используя схему (для создания секционированной таблицы). Что касается того, какой из вариантов предпочтительнее (даже если эта таблица в будущем станет секционированной), то все зависит от того, как таблица будет заполняться и сколькими секциями вы собираетесь манипулировать. Наполнение кучи (heap) и последующее создание в ней кластерного индекса, вероятно, обеспечит лучшую производительность, чем загрузка в таблицу, содержащую кластерный индекс. Кроме того, в мультипроцессорных системах вы можете загружать данные в таблицу параллельно, и затем тоже параллельно строить индексы. В качестве примера создадим таблицу Orders и загрузим в нее данные, используя операторы INSERT … SELECT. Чтобы создать таблицу Orders в качестве секционированной, определите схему секционирования в выражении ON оператора CREATE TABLE.
Поскольку таблица OrderDetails собирается использовать ту же схему, она должна включать в себя столбец OrderDate.
На следующем шаге в таблицы загружаются данные из новой учебной базы данных AdventureWorks. Убедитесь, что вы установили базу данных AdventureWorks.
Теперь, когда вы загрузили данные в секционированную таблицу, Вы можете воспользоваться новой встроенной системной функцией для того чтобы определить секцию, на которой будут располагаться данные. Следующий запрос для каждой из содержащих данные секций возвращает информацию о том, сколько строк содержится в каждой из секций, а также минимальное и максимальное значения поля OrderDate. Секция, которая не содержит строк, не попадет в итоговый результат.
И наконец теперь, после того как вы загрузили данные, Вы можете создать кластерный индекс и внешний ключ (Foreign key) между таблицами OrderDetails и Orders. В данном случае кластерный индекс будет построен на первичном ключе (Primary Key) точно так же, как вы идентифицируете обе эти таблицы по их ключу секционирования (для OrderDetails к индексу Вы добавите столбец LineNumber для уникальности). По умолчанию при построении индексов на секционированной таблице происходит их выравнивание по отношению к секционированной таблице согласно той же самой схеме секционирования; явно задавать схему не обязательно.
Полный синтаксис, определяющий схему секционирования, выглядел бы так:
Объединение секционированных таблиц Когда объединяются выровненные таблицы, SQL Server 2005 может выбирать между объединением таблиц за один шаг, либо в несколько этапов, когда вначале объединяются отдельные секции, а затем подмножества складываются. Но независимо от того, как объединяются секции, SQL Server всегда пытается оценить, насколько возможно исключить из объединения какие-нибудь секции. В следующем примере данные запрашиваются из таблиц Order и OrderDetails, созданных в предыдущем сценарии. Запрос возвращает данные о продажах только за третий квартал. Как правило, в третьем квартале потребительский спрос на товары невысок; однако в третьем квартале 2004 года, напротив, был зафиксирован один из самых высоких уровней объема продаж. В данном случае нам интересно, была ли (в третьем квартале) какая-либо взаимосвязь между объемами заказов и датами продаж. Для того чтобы гарантировать, что выровненные секционированные таблицы при объединении извлекают выгоду из исключения секций, Вы должны убедиться, что установили диапазоны секционирования для каждой из таблиц. В данном случае, поскольку первичный ключ (Primary Key) таблицы Orders является составным (OrderDate + OrderID), объединение между таблицами Order и OrderDetails должно производиться не только по равенству OrderID, но и по равенству дат. SARG (Search Argument - Аргумент Поиска) будет применен к обеим секционированным таблицам. В итоге, наш запрос будет выглядеть следующим образом:
На Рисунке 14 представлено несколько ключевых моментов, на которые стоит обратить внимание, изучая реальный или расчетный планы исполнения. Для этого нам придется воспользоваться SQL Server Management Studio. Обратите внимание на значения "Estimated Number of Executions" (расчетное количество выполнений) или "Number of Executions" (количество выполнений) для обеих таблиц. В нашем случае, мы рассматриваем один квартал, т.е. три месяца. Данные за каждый месяц располагаются в своей собственной секции, и поэтому поиск данных выполняется трижды - по одному разу для каждой таблицы. 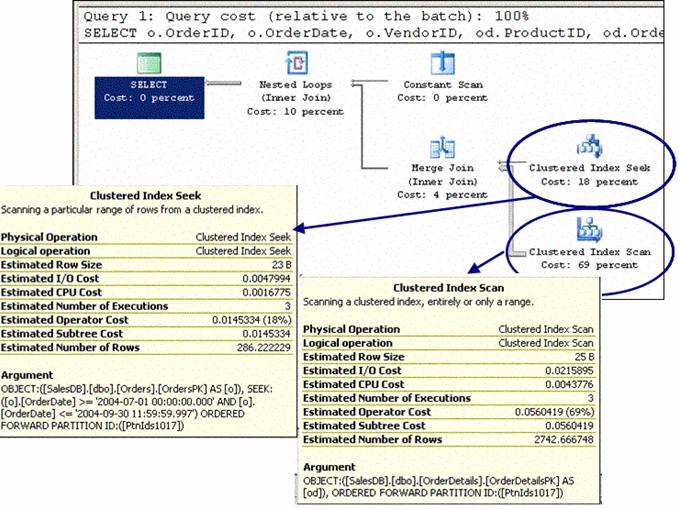 Рисунок 14: Количество выполнений Как можно увидеть из Рисунка 15, SQL Server устраняет все лишние секции и оставляет только те, которые содержат необходимые данные, для чего анализирует PARTITION ID:([PtnIds1017]). Вы можете задаться вопросом, откуда взялось выражение PtnIds1017? Если вы обратите внимание на значок "Constant Scan" в верхней части плана исполнения, то увидите что в списке аргументов у него VALUES(((21)), ((22)), ((23))). Это не что иное, как номера секций. 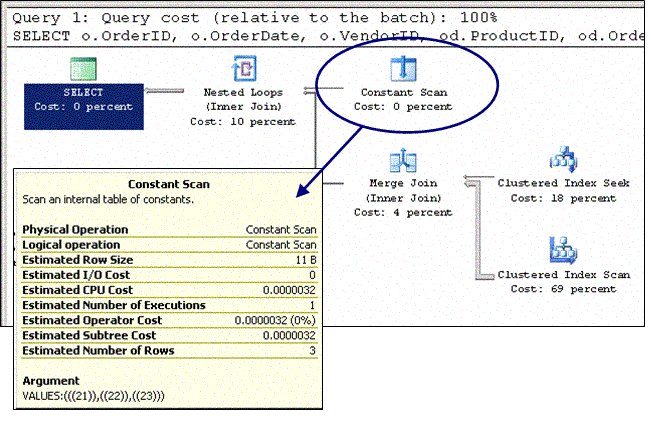 Рисунок 15: Количество выполнений Для того чтобы проверить, что данные располагаются в тех (и только в тех) секциях, вы можете воспользоваться слегка модифицированной версией созданного ранее запроса, а заодно обратиться к новым встроенным системным функциям для работы с секциями.
Из Рисунков 14 и 15 видно как происходит исключение секций. Если секционированные таблицы и индексы выровнены по отношению к таблицам, с которыми объединяются, то могут использоваться и другие методики оптимизации. SQL Server может выполнить "множественные" объединения, объединив вначале все секции. Предварительное объединение выровненных таблиц В приведенном ранее запросе SQL Server не только исключает лишние секции, но также производит объединение между оставшимися секциями - по отдельности. Помимо наблюдения за количеством обращений к таблицам во время исполнения запроса вы также должны были обратить внимание на значок "merge join". Если вы присмотритесь, то увидите, что объединение слиянием (merge join) также выполняется три раза. 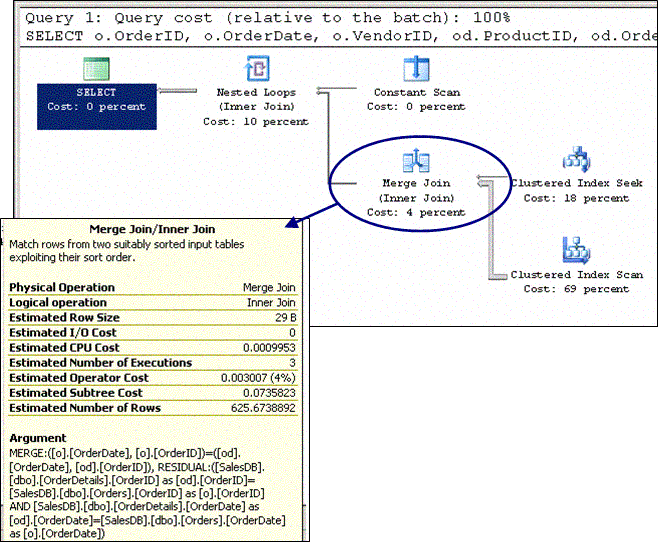 Рисунок 16: Объединение секционированных таблиц Обратите внимание, на Рисунке 16 представлен еще один элемент - "nested loops" (объединение "вложенных циклов"). Может показаться, будто это объединение выполняется после объединения слиянием, но на самом деле оказывается, что это объединение является избыточным. Идентификаторы секций к тому моменту уже были переданы для поиска в каждую из таблиц, и это заключительное объединение только сводит вместе две порции данных, удостоверяя, что каждая из них придерживается идентификатора секции, объявленного в начале (в выражении "Constant Scan"). Как только станут доступными данные следующего месяца (в
нашем случае это Октябрь 2004), Вам потребуется
руководствоваться определенной последовательностью действий,
для того чтобы используя существующие файловые группы
"двигать" ("включать"/"выключать") в них данные. По данному
сценарию в файловой группе FG1 в настоящее время находятся
данные за октябрь 2002. Теперь, когда появились данные за
Октябрь 2004, у Вас есть два пути, в зависимости от доступного
Вам дискового пространства и требований к архивации. Помните,
чтобы "включение" или "выключение" секции из таблицы прошло
быстро, оно должно затрагивать ИСКЛЮЧИТЕЛЬНО метаданные.
Другими словами, новая таблица (источник или целевая - т.е.
скрытая секция) должна быть создана в переключаемой файловой
группе. Если Вы планируете продолжать использовать те же самые
файловые группы, в данном случае FG1, то тогда Вы должны
будете решить, как управлять дисковым пространством и
требованиями к архивации. Если у Вас достаточно места на
диске, то Вы можете загрузить текущие данные (октябрь 2004) в
FG1, не удаляя данных, которые будут заархивированы (октябрь
2002).
Рассмотрим каждый из шагов более детально. Дополнительно каждый шаг содержит примечания, помогающие автоматизировать процесс с помощью динамического SQL. Управление "включаемой" каскадной таблицей
Управление второй каскадной таблицей ("выключаемой")
Исключите старые данные из секционированной таблицы и добавьте новые.
Поскольку в следующем (и заключительном) шаге все данные архивируются, то каскадные таблицы нам больше не нужны. DROP TABLE - самый быстрый путь удалить эти таблицы.
Произведите резервное копирование файловой группы Выбор того, что архивировать в последнем шаге, зависит от вашей стратегии резервного копирования. Если вы выбрали стратегию, основанную на резервном копировании файла или файловой группы, то тогда должно быть выполнено резервное копирования файла или файловой группы. Если выбрана стратегия полного резервного копирования базы данных, то тогда должно быть выполнено полное или разностное резервное копирование.
Секционирование списка - данные из регионов Если в вашей таблице собираются данные из нескольких
регионов, а анализ часто производится в разрезе одного
региона, или Вы получаете данные от каждого региона только
время от времени, подумайте об использовании определенного
рода "диапазонных" секций, имеющих форму списка. Иными
словами, Ваша функция секционирования явно определит значение
региона для каждой секции. В качестве примера рассмотрим
испанскую компанию, клиенты которой находятся в Испании,
Франции, Германии, Италии, и Великобритании. Сведения о
продажах компании всегда анализируются в разрезе страны,
поэтому таблицы удобно секционировать на пять частей, по одной
для каждой страны.
Следующим шагом мы создаем функцию. Она является LEFT-функцией и описывает только 4 секции. В нашем случае список будет включать все страны за исключением Великобритании, поскольку она является последней по алфавиту в этом списке.
Для того чтобы в будущем данные создавались в соответствующих файловых группах, названия файловых групп в схеме секционирования также должны быть перечислены в алфавитном порядке. В данном случае должны быть перечислены все 5 файловых групп.
Теперь таблица Customers может быть построена на основе новой схемы секционирования CustomersCountryPScheme.
SQL Server 2005 предлагает Вам секционирование в качестве простого инструмента управления большими таблицами и индексами. Секционируя большие таблицы и индексы вы получаете возможность манипулировать подмножествами ваших данных извне секции - тем самым позволяя упростить управление, улучшить производительность, и абстрагироваться от логики приложения; схема секционирования является полностью прозрачной для приложения. Если ваши данные логически сгруппированы (в диапазоны или списки), а тяжелые запросы должны анализировать эти данные в рамках группировок, а также управлять вставкой и удалением, то наилучшим решением будет использование механизма секционирования. Если же Вам не приходится анализировать большие объемы данных в разрезе диапазонов или если все Ваши запросы обращаются к большей части данных (или даже ко всем), то тогда, с точки зрения простоты управления, обычное использование нескольких файловых групп вместо секционирования будет пожалуй более удобным решением, также улучшающим производительность Вашей базы данных. |
|
|
| ||||||||||||||||
|